With 14,000,000 downloads and counting, and almost 500,000 active installations at the time of writing, WP Google Maps (by Code Cabin) is the largest application I’ve been in charge of to date.
For anyone interested to know what I did in my time working on WP Google Maps, I’ve put together this page to illustrate what I brought to this plugin.
Please see my CV for more information about my roles and responsibilities within Code Cabin, this post focuses purely on the engineering and code itself.
Table of Contents
Version 6
Whilst version 6 did boast a very impressive feature set, especially compared to it’s competitors, there was a large amount of re-factoring needed to get the code base into a maintainable state before any new features could be worked on.
Monolithic, WET code
Version 6 had a lot of WET code, some blocks were hundreds of lines long. In my first few weeks with Code Cabin this wasn’t immediately evident, linting tools wouldn’t work with the structure as it was, so it wasn’t until this began manifesting itself in bugs that the layout started to become apparent.
For example, the plugin offers a choice of DB (inline JS) marker loading, or XML marker loading. The plugin has marker categorisation, and a radial search. Version 6’s front-end JavaScript was one monolithic file, which looked something like this:
// Function to show markers
function()
{
if(/* Loading markers from inline JS */)
{
foreach(/* JS data */)
{
if(/* No search radius, no categories */)
{
// Create marker and display
}
else if(/* No search radius */)
{
if(/* Marker inside selected categories */)
{
// Create marker and display
}
}
else if(/* No categories */)
{
if(/* Marker inside specified radius */)
{
// Create marker and display
}
}
else
{
if(/* Marker inside selected categories and marker inside specified radius */)
{
// Create marker and display
}
}
}
}
else if(/* Loading markers from XML cache file */)
{
foreach(/* XML data */)
{
if(/* No search radius, no categories */)
{
// Create marker and display
}
else if(/* No search radius */)
{
if(/* Marker inside selected categories */)
{
// Create marker and display
}
}
else if(/* No categories */)
{
if(/* Marker inside specified radius */)
{
// Create marker and display
}
}
else
{
if(/* Marker inside selected categories and marker inside specified radius */)
{
// Create marker and display
}
}
}
}
}This was problematic, because, for example, if a bug emerged in the category filtering code then it would be fixed, then later seem to re-emerge. This was a frequent occurrence at first because fixing a bug in the XML filtering category logic would need to be repeated in the inline JS block, which was easy to overlook for anyone unfamiliar with the code.
WP Google Maps offers a Pro add-on, there was a great deal of code that was repeated from Basic in Pro, where the design had made true extensibility practically impossible, resulting in WET code actually being necessary in some places. The first decision I took as Lead Developer on this plugin was that this needed to be re-arranged so that in the very least, we didn’t have repeated, high maintenance blocks of logic.
Interleaved logic, content and presentation
Another problem with the earlier versions was a lot of mixed logic (PHP/JS), content (HTML) and presentation (CSS).
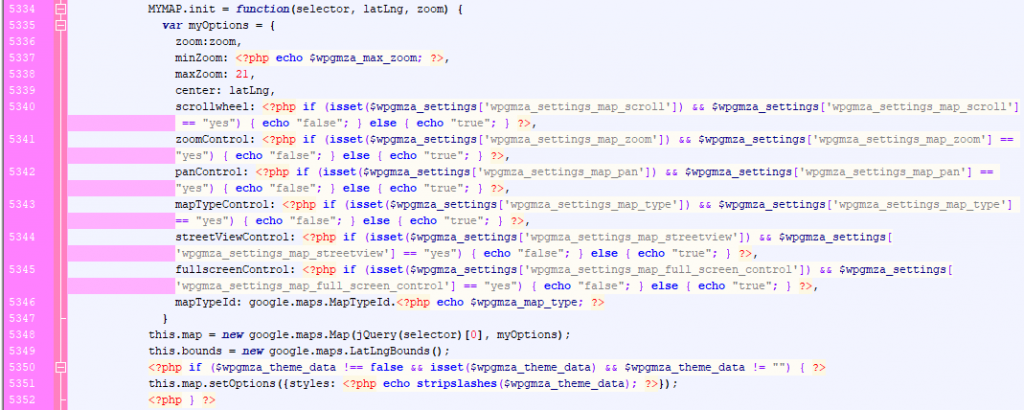
For an experienced developer, escaping and switching between these “in real time” is do-able, however there are other problems that arise from this approach, most notably,
- Unexpected characters from user input being outputted from PHP could produce malformed HTML, or worse JS syntax errors. For example, the end users could edit raw polygon data if they wished to do so, entering anything outside of the specified format would usually produce a JavaScript error.
- Fields being serialized in an inconsistent way, for instance, some fields would use stripslashes when saving. Others would not. This would not emerge until a user started adding quotes into that field, and would quickly find they would accumulate and balloon in the database. This lead to hundreds of different calls to stripslashes being added with no apparent pattern.
- No templating or dynamic handling of settings means that if you want to add a new control to the interface, you will have to create PHP to render the control in the appropriate state,
- Also because of the above, you would have to write PHP to receive and write the value of the control back into the database explicitly, each time you add a new control.
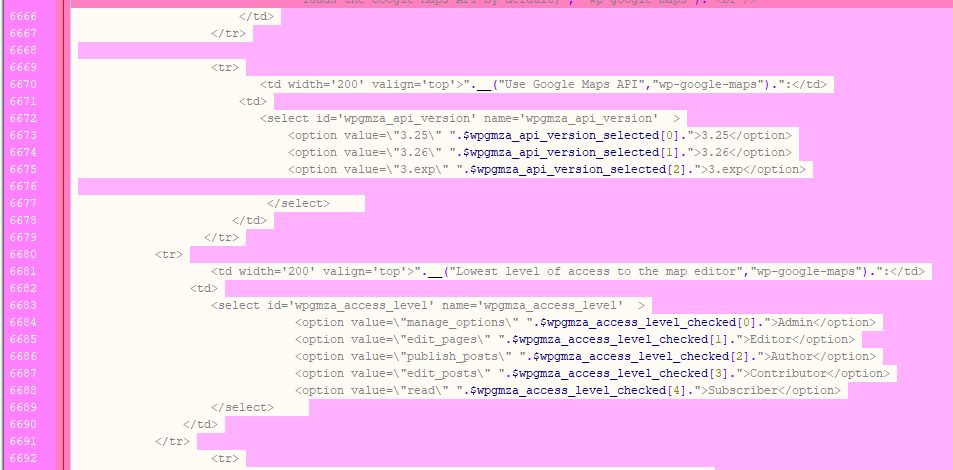
The plugin literally has hundreds of different settings, some with inconsistencies in naming, inconsistencies in the way values are used to represent settings and lack of standardisation in general, so refactoring this particular aspect of the plugin, in a manner which keeps the very substantial user base happy, was an absolutely mammoth task.
Suboptimal filtering
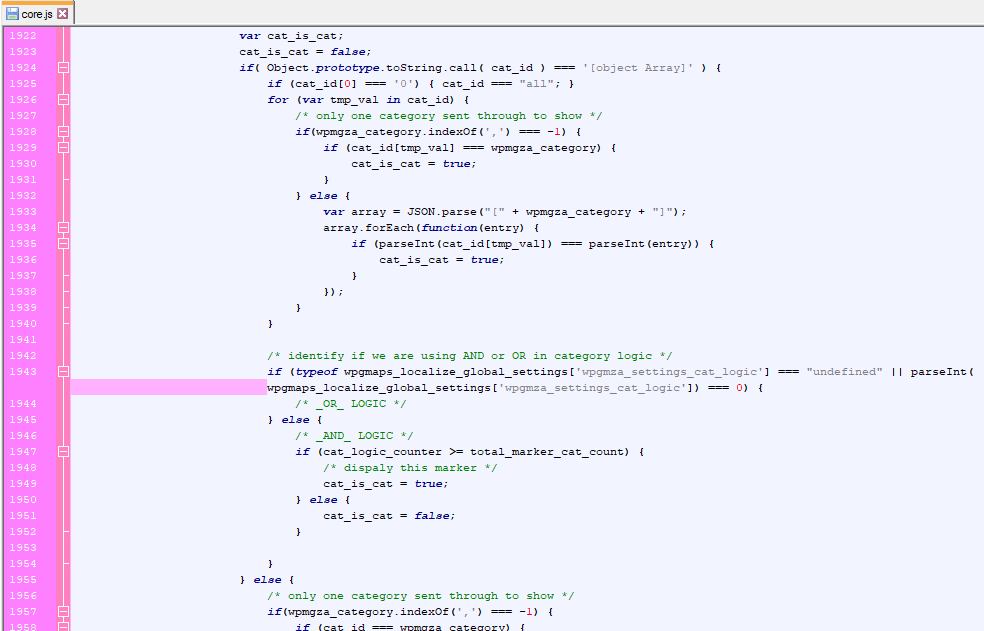
The plugin supports various forms of filtering, for example, filtering by an address and radius, keywords, or categories.
Historically, this filtering would be performed by hand-rolled JavaScript which would take care of the filtering. I took the decision later on to move this onto the database, which does obviously move load onto the server, however the filtering queries are very simple compared to the legacy JavaScript, don’t stall the browser, and are an appropriate use of the database rather than using our own JavaScript which required maintenance and debugging.
Lack of CRUD and other interfaces
Version 6 worked directly on the plugins database tables, with no exceptions. All the code that dealt with reading, serializing and writing data from the client (browsers) to the database and back worked exclusively with non-modular, purely procedural code. Many code points addressed the database directly, with explicit sanitization and escaping (as opposed to prepared statements) and little use of WordPress’ database helper functions.
This became especially problematic because adding code to one aspect of the plugin would often require a developer to add code elsewhere in a seemingly unrelated section of code.
For example, the process of adding a new field to the marker table would require one to add additional code to transmit that data to the browser, but would also require one to add code to the data exporter. Because of a lack of documentation on this, it could be quite easy to make avoidable mistakes here.
The lack of classes, interfaces and generally standardised code made generating meaningful, structured documentation impossible with version 6.
Lack of extensibility
Version 6’s JavaScript engine was built almost entirely around about half a dozen very large functions.

Such a design leads to lack of extensibility, because it was impossible to customise atomic parts of the plugins functionality without overriding the entire function – which would inevitably lead to users editing code themselves, which would ultimately either lock them out of updates, or cause the overrides to fail as the code base changed.
Version 6’s PHP was built entirely on functions in the global scope, with almost no use of meaningful WordPress hooks.
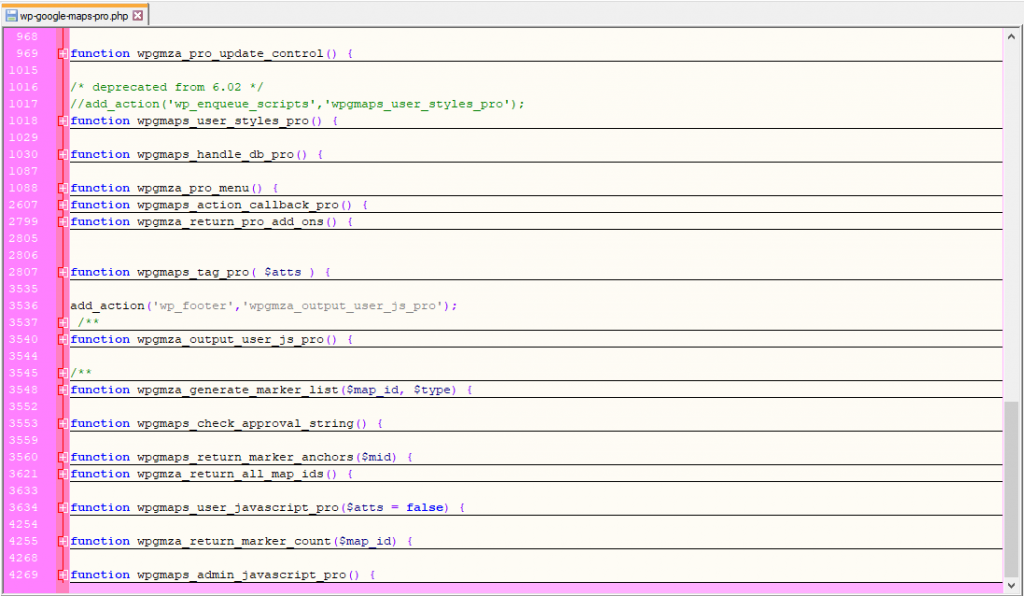
I refactored both the server side and client side code into modules which use the Factory Design method, which not only allowed the plugin to be fully extensible, but would also pave the way for making the plugin and Premium add-on share a great deal of code, leading to a DRYer code base.
Version 7+
Mostly leaving the plugins feature set to one side, I’m focusing on the software architecture itself in this post, however I made two very significant changes to my first major release with WP Google Maps.
Version 8 includes many, many new features, and also builds on the changes mentioned in this section, moving towards fully modular JavaScript, fully modular PHP (in future releases) and full separation of content, logic and presentation.
Object-oriented refactor
Under the hood, I undertook some major refactoring for the version 7 release. As anyone reading with experience will know, this is a thankless task that is supposed to be seamless (eg unnoticed) to the end users.
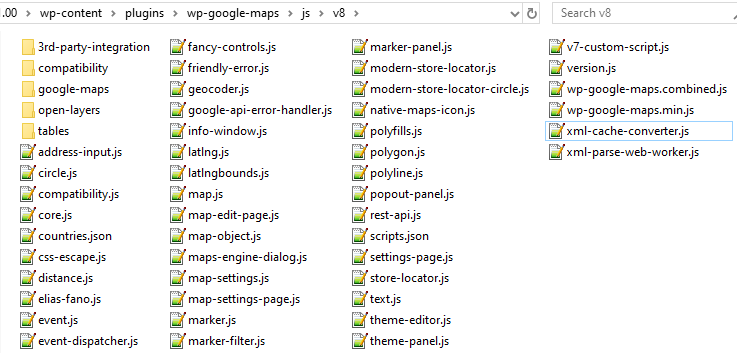
The benefits of this re-factor is that the very large functions in version 6 can be broken down in to much smaller components, placed in well named functions, on well named modules, in separate files with descriptive names. The legacy code was extremely difficult to navigate, even as an experienced developer, quite often your best tools for tracking down a particular bit of code would be find in files and a regular expression, with no developer documentation or atomic functions with meaningful names to help you find a particular set of functionality.
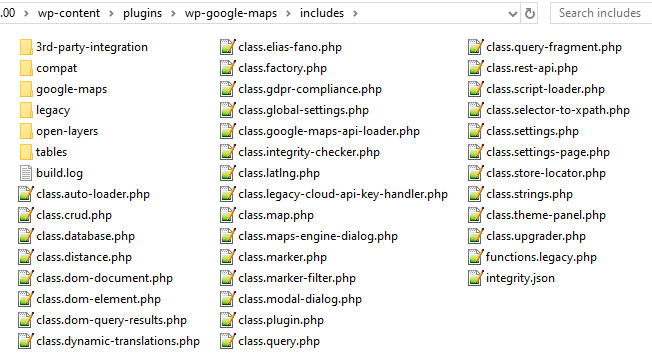
Another huge bonus of this approach is that it massively improves the plugins extensibility. More on that shortly.
REST API
I started building a REST API for WP Google Maps in version 7. The initial purpose of this was to facilitate asynchronous, paginated marker listings for our “power users” with a large number of markers.
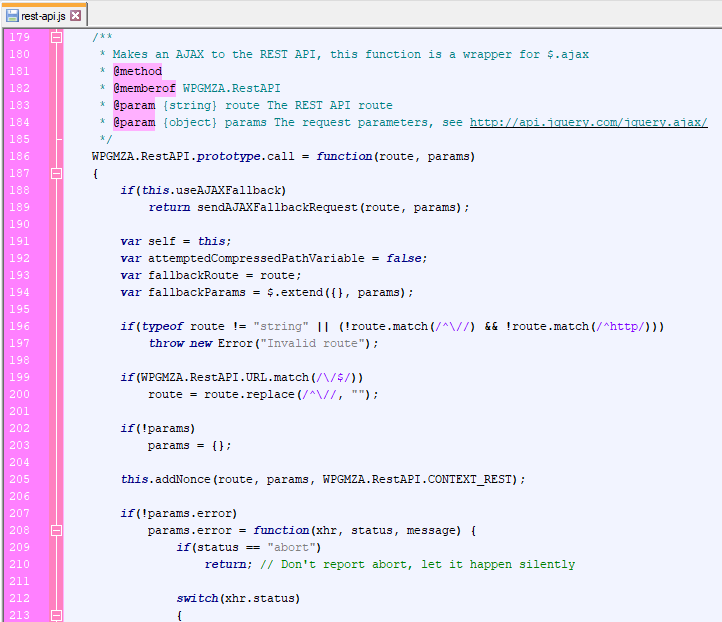
Version 6 would output the HTML for the entire listing directly into the page body, which could cause high output times server side, and high parse and render times client side. This became especially problematic for users with many thousands of markers, as it would lead to browser stalling, or worse, the PHP execution time limit being hit during rendering.
Version 7 deprecated all marker listing code and introduced REST based modules to handle all this functionality.
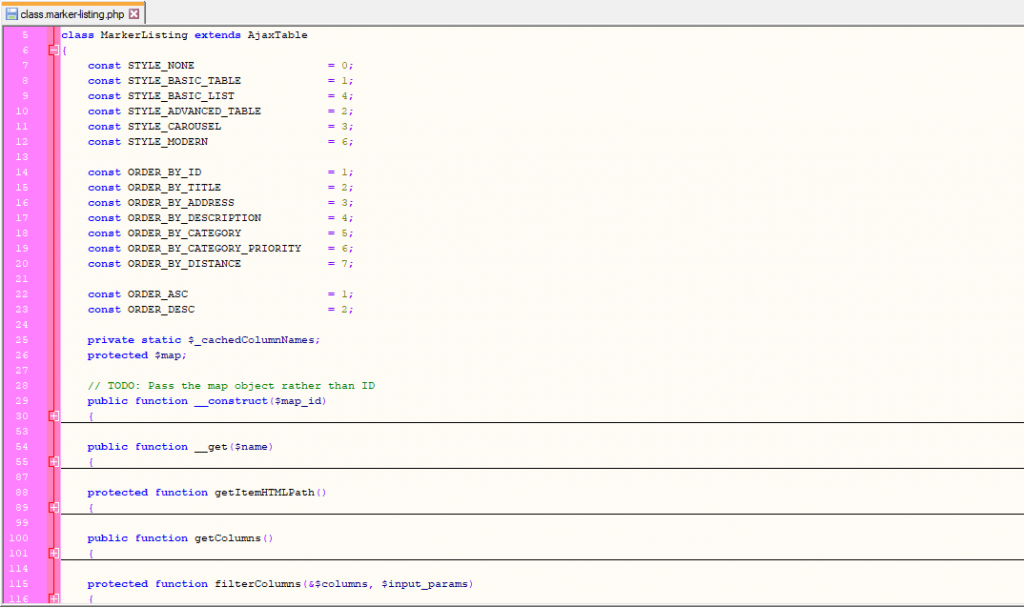
This had to be done very carefully, so as not to break JavaScript and CSS associated with the marker listings – both internal code, and snippets we’d given out to the customers over time.
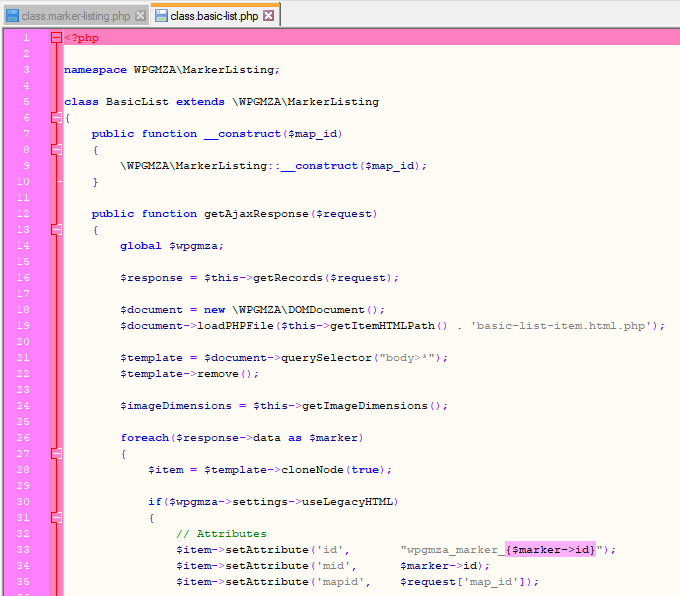
This was hugely beneficial for the plugin in general, but especially for the marker listings. Having a very large number of markers would no longer stall the browser on parsing HTML, or cause long load times, or even worse – a blank page due to PHP hitting it’s execution time limit.
The REST based marker listing system is asynchronous, features server-side pagination rather than transmitting all items, and extends from base classes which provide functions for searching and sorting the list items in a consistent way across all child classes, where previously this was not the case.
Query builder and server-side filtering
The REST API would later (7.11.*) go on to be used to facilitate marker filtering, with all the JavaScript that previously performed this removed.
The filtering components (store locator, category filter, custom field filters), which are now fully modular and extend from an event dispatcher module, will emit an event when filtering parameters change.
The filtering module will listen for these events, and when the filtering parameters change, a REST request is sent out to the server.

This request is received by the markers REST endpoint, which instantiates a marker filter and passes these parameters to the filter.
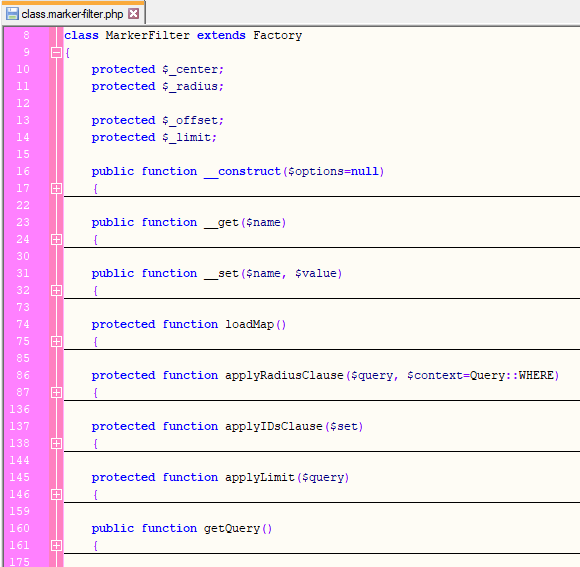
The marker filter uses these parameters to build a query, which is then used to fetch the ID’s of all markers which fit the specified parameters. The ID’s are returned to the browser via REST, which can then show and hide markers based on the returned ID’s.
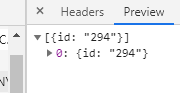
The server-side marker filtering massively outperforms the legacy JavaScript, it’s handled by a couple of dozen lines of code rather than hundreds of lines, so it’s more maintainable and easier to work with. It also means that the results are cachable via REST cache plugins or a CDN.
JavaScript modules
Version 7 was the first version to introduce modules for JavaScript. This was mainly done to facilitate OpenLayers support – by creating wrappers instead of using Google’s modules directly, and by using the Factory Method design pattern, I was able to achieve engine independence for our legacy core code.
This meant that the logic in the core code could stay without a total refactor, but wrappers with methods and properties matching Google’s modules could facilitate OpenLayers support through the plugin.
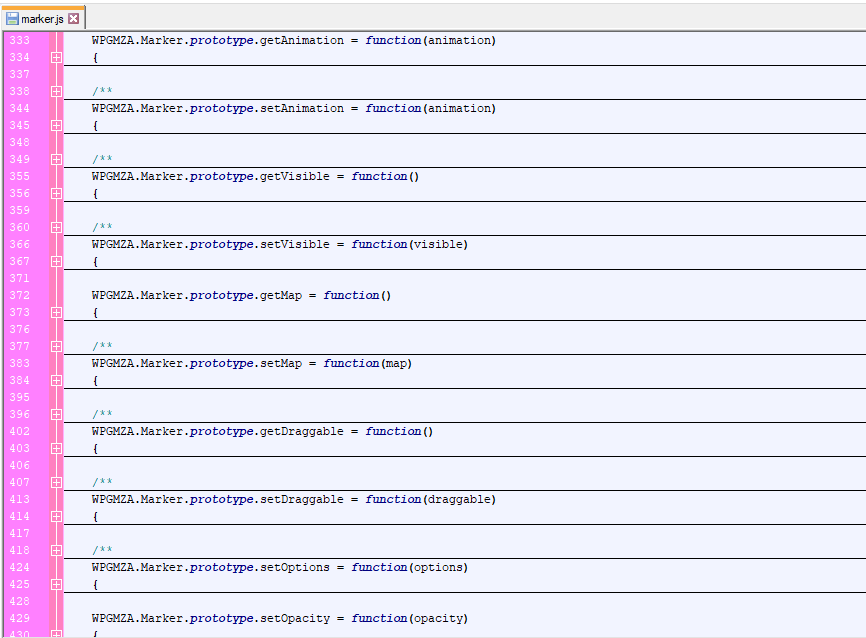
This also meant that JavaScript snippets we had given out to customers to implement custom behaviour on, for instance, markers, would continue to work seamlessly with our new wrappers.
This also meant that the end user could have their own modules which subclassed our wrappers, which allowed for further, fine tuned and external customisation of many aspects of the plugin.
It also opens the door for small, atomic customisations, by allowing the user to add external JavaScript snippets to override various functions on these modules. This allows for easy customisation of almost any conceivable aspect of the plugin, in a forward compatible, and external manner.
CRUD classes
Version 7 implements a CRUD base class, which many other classes are built upon in version 7.
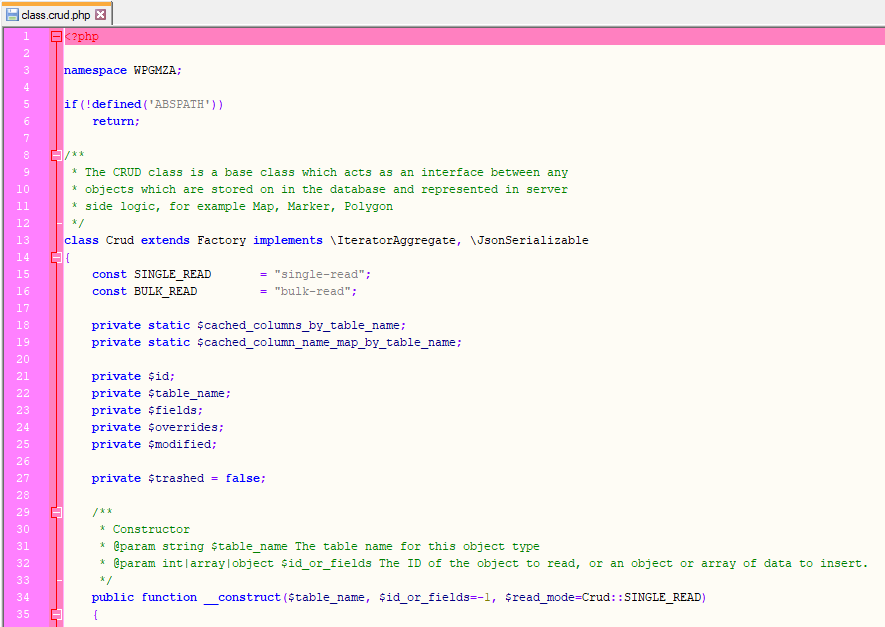
For instance, when a marker is deleted, rather than a query being run directly on the database when the command is received, the trash method is called on the target ProMarker. The code which removes the marker record itself from the database is in the base class, ProMarker adds extra code here to remove the markers category and custom field data.
This means a marker can cleanly be removed in one function call, and that code which removes markers (eg when manually deleted, or when overwriting during an import) can be DRY and consistent wherever that behaviour is desirable.
In addition, when a Map is trashed, it will call the method on all markers belonging to that particular map. Not only is the code DRYer and more elegant, it makes maintaining a clean database much easier for developers working on the plugin.
CRUD implements magic methods to allow developers to get and set data directly from the database on any object (eg marker) which extends CRUD. This makes it very easy to work with data without touching the database directly, which is a great compliment to the REST API – you can simply iterate over $_POST and use the keys and values on the target Marker, no query, no hassle.
Factory Method design pattern
One of the main problems with version 6 was the lack of extensibility. Large amounts of code were repeated in the premium add-on (eg one function for the plugin shortcode, a separate function for the premium shortcode which contained the entire body of the basic function.
The legacy JavaScript was much the same. Extensibility was difficult at best, and making small changes to the functionality would almost always involve users having to modify the source themselves, which would have to be re-done after each update, or lock the user out of updates completely. It’s quite surprising how commonplace this practise is in the WordPress plugin and theme community. Unfortunately, in the long term, this approach will create more problems than it solves.
Version 7 implements the Factory Method in JavaScript by mandating that all factory objects are created with createInstance, and never directly instantiated with new.
This means that when functionality, for example the store locator, is implemented on the basic plugin, the premium add-on can very easily override the MarkerFilter with a ProMarkerFilter as pictured below.
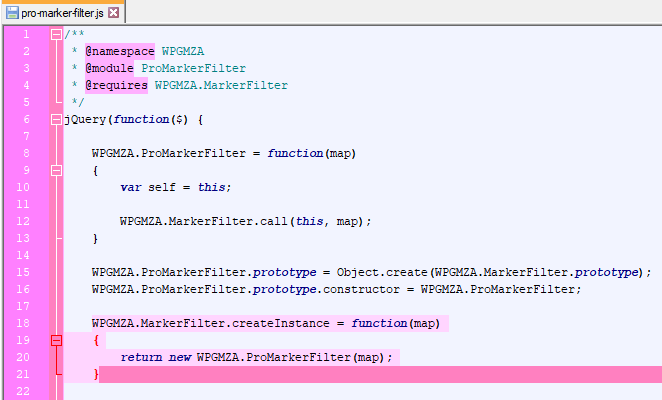
This allows the basic store locator to easily work with a ProMarkerFilter, which means that the marker filtering is truly extensible and doesn’t have to be repeated, and can also still be leveraged by the basic plugin with no repetition or quirks used.
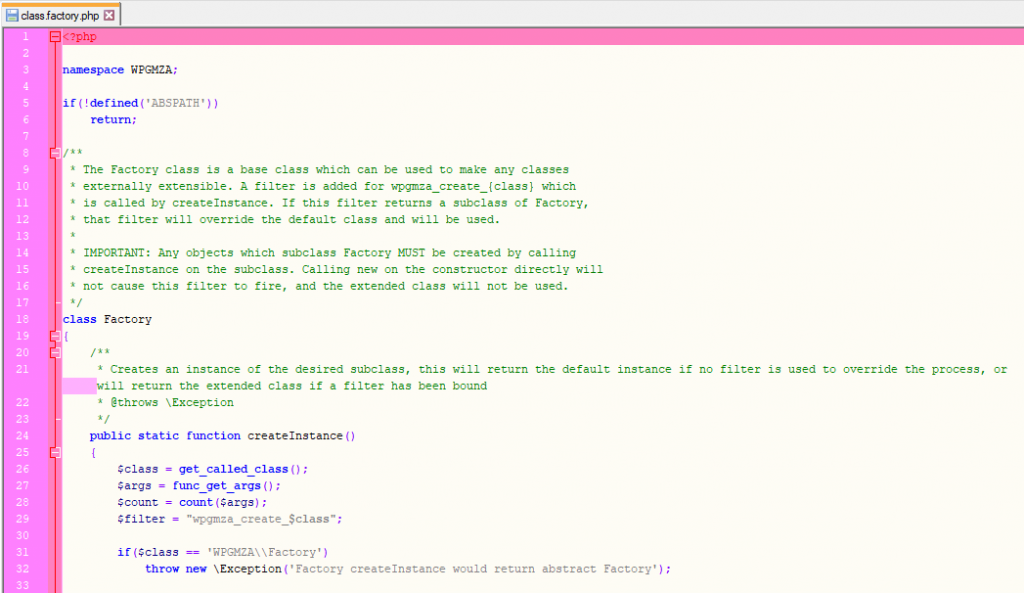
This is slightly more tricky server side, since PHP does not provide any mechanism to override createInstance. I did look into late static binding for this, however ended up using WordPress’ filter system to implement this.

This means that anywhere the basic plugin code creates a Marker using createInstance, a ProMarker will be instantiated and returned.
This allows systems such as the basic REST API to return ProMarkers without any hassle, which allows code in the basic REST API to return markers with category and custom field data, and other data specific to ProMarker.
DOMDocument HTML handling
Historically, WP Google Maps worked with raw string concatenation in order to render HTML pages and panels.
This is fairly commonplace in WordPress plugin development, however as the plugin becomes larger and more complex, it’s desirable to use a more dynamic, robust approach – software that does heavy work with DOM trees should use a DOM library for parsing, manupulation and rendering.
This also helps to achieve separation of content and logic.
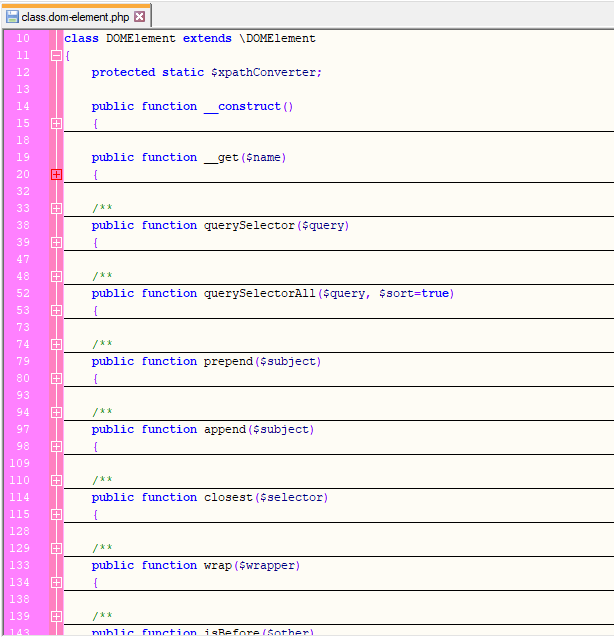
Using the DOM classes allows easy manipulation of DOM data, it prevents any user input from producing invalid HTML (where concatenating strings requires explicit escaping), gives the server some kind of context on what data is being POSTed based on the content of the form, and in later versions allows the plugin to dynamically populate a HTML form with key value pairs (eg the plugins settings page and map edit page for any given map).
Version 7 started this process with all new components using this approach to HTML DOM, with a view to fully convert all the plugins existing HTML to use this approach moving forward.
Build pipeline and minification
Historically, WP Google Maps used a single, monolithic JavaScript file to control all functionality on the front end, and a second file to do the same on the back end.
Version 7 introduces discrete modules, with dependency order dictated by header comments. We use an in house script loader to handle the build process, and command line tools to handle the minification process before deployment.
This massively improved the readability and maintainability of the plugin code, allowing us to use well named files rather than all functionality being in a monolithic file. It also makes sharing common behaviour across the front end and back end possible in a DRY manner, where repeated code was used in the past.
Epilogue
As you can see, during my time with Code Cabin, I took a considerable number of steps to improve the software architecture, in order to help make the plugin more readable, maintainable, easier to navigate, debug and generally provide a better foundation upon which new features can be built.
Version 8.1 will see the first release with fully modular JavaScript, which I’m hopeful to see go live soon. This was, sadly, the last engineering I’ve done to date for Code Cabin.
8.1 also sees complete separation of content, logic and presentation for both the map edit page, and the main settings page. Both these components represent the overwhelming majority of PHP and HTML involved in the plugin. This should put the team on a solid footing moving forwards, making it much easier for the juniors and senior developers alike to work with, and paving the way for focusing on enhancing the feature set – rather than getting bogged down in explicitly handling data, escaping and sanitizing data, and the legacy workflow in general.
I’ve left the WP Google Maps team with a full refactoring plan which shows, in an itemised manner, exactly what steps I would have taken had I been able to continue with the team. I hope to see this followed in the future and look forward to seeing them reap the benefits of this approach.
I never intended to be a WordPress developer, as I’m used to working with cleaner frameworks, however it was a pleasure in doing so and I value the experience this project gave me, especially considering WordPress’ market share.
The sheer size of the user base made fully refactoring the entire plugin during my three years on the project impractical to do in large steps – I had to take great care in doing this and make the most incremental changes possible.
I also opted not to complicate the software by bringing in components from Packagist and Node, complicating the build pipeline in the process and adding dependencies which we’d then have to monitor. In my time on WP Google Maps, I was mindful of the juniors who have enough to learn about without worrying about the additional gotchas that come with these tools. It would also have been largely impossible to marry these up with the legacy code, once the re-factor is complete then it is my hope moving forward that the team can see the benefits of this new approach and start to integrate more modern tool chains into the plugin.
Another change I would recommend is storing geometric features as meta data associated with a post, rather than in tables owned by the plugin. Perhaps a choice of storage engine moving forwards could facilitate this. Again, sadly, considering the plugin had well over 250,000 users and I was quite restricted with regards of how significant changes can be in any given update, this simply wasn’t something I was able to achieve in a compatible manner in my time on this project, but I recognise that this approach would be superior.
WP Google Maps was a big part of my life, it’s certainly the largest active user base I’ve worked with in any projects I’ve worked on. I like to think my time here reflects very well on my abilities to debug, refactor in a stable manner, and make the right architectural decisions, not just based on my experience in engineering, but also based on the goals the team had in mind for the plugin.